
With the TableView transform, data from a source can be filtered and sorted. The data source can be an extract or transform in the project. If a tree-type transform is used, you'll need to select a tree format; see Overview of Tree Formats for abbreviations and usage.
Note that TreeView transform is more flexible than the TableView transform and can also preserve the tree structure of the source.
Filtering
Filters require the following options to be set:
Input
The input for the filter is a column in the data source. The available columns are shown in a dropdown list in the input field.
Filter type
Various filter lines to the same input column are evaluated like a rule chain with the filter types "accept" and "deny". If only accept filters are used, this behaves like a logical OR.
Operator
Comparison operators can be used on element names.
equal The element entered here will be filtered. Filter behavior depends on the type of data:
- String: the filter must be exactly equal to the source value.
- Decimal number (floating or double): the filter value must be the most minimal representation of the value. For example, if the source value is 1.0, the filter value must be 1. If the source value is 1.5000, then the filter value must be 1.5.
- Non-decimal number (int or long): the filter value must be exactly the same as the number.
- Boolean (true/false): the filter must be "true" or "false" as appropriate.
inAlpharange Alphanumerical values in a particular range are filtered. Example: [A100,D200]. The short GIF below shows how this functionality works with dates.
inRange Numerical values in a particular range are filtered. Example: [1000,2000] Other examples:
- “[100,200]” - inclusive range: 100, 101.....199, 200
- “(100,200)” - exclusive range: 101, 102, ... 198, 199
- “[100,]” - inclusive half-open interval: numbers greater or equal to 100
- “[,100)” - exclusive half-open interval: numbers lower than 100
isEmpty Empty values (blank, space, or multiple space values). For this operator, the Value field should be left blank. isNull The condition is true for NULL values but not for (possibly trimmed) empty strings. like Filters the dimension elements according to regular expressions. This operator is case-sensitive. You can change that by using the (?i) modifier at the start of a regular expression.
After using the regular expression, the data preview must look like in the example below:




Value
The element you want to filter for in the dimension. This field is required for all operators except "isEmpty".
Logical operator
- and: a data record is in the filter result when it matches the conditions of all filtered columns.
- or: a data record is in the filter result when it matches the conditions of at least one filtered column.
The logical filter operator "and" is the default.
Sorting
The columns of a data source can be sorted. Elements can be sorted in ascending or descending order, with or without case sensitivity. The sorting is processed BEFORE an eventual filtering of start and end rows.
Input
Input can be selected from the dropdown list of source data.
Order
Elements can be sorted in ascending or descending order, with or without case sensitivity. Multiple sort criteria can also be defined.
Note that sorting is numerical only when the sorted column has number sequences as value type, e.g. double / integer numbers; otherwise, the default behavior is alphanumeric order, that is, a lexical / string-based sorting. For example:
- Lexical sorting: 12 < 5 < 5.0 < 6
- Numerical sorting: 5 < 6 < 12
Target
Here you can specify how each field in the data source maps to the output. This involves setting the Field name (the name of the column in the output) and the Input (the source of the data, which can be another field or a constant value).
Note: when the input is coming dynamically from the source or transform, but the field name is left empty, the name of the source column / function is used for the field name. When the target is manually defined as constant, then the name "constant" is chosen instead of the value from the input field. Adding more than one constant column results in error, because there would be two columns with the name "constant."
Other settings
Start line
The result starts in the source row with this index. Previous rows are filtered out. If not set, all rows are taken from the beginning.
End line
The result ends in the source row with this index. Subsequent rows are filtered out. If not set, all rows are taken up to the end.
Skip rows operator
- none: every row that passes into the transform will be included in the output table.
- isEmpty: skips rows where the field values are empty strings ("").
- isNull: skips rows where all the field values are null, i.e. the field doesn't exist or is undefined in that row.
Use caching
If caching is activated, the complete output of the extract is temporarily stored during the first call of the extract, using an internal H2 database. Subsequent calls of the extract read directly from the cache without connecting to the underlying source system of the extract. If the extract or the underlying connection contains variables, a separate cache is build for different values of these variables.
See Caching in Extracts and Transforms for more information.
Examples
| Data source |
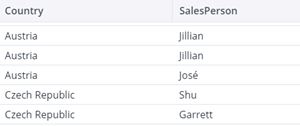
|
|
| Filter type “accept” |
|
|
| Result with logical operator “and” |
|
|
| Result with logical operator “or” |
|
|
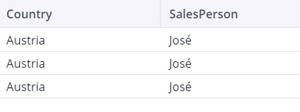
| Filter type “deny” |

|
|
| Result with logical operator “and” |
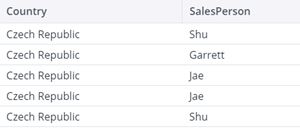
|
|
| Result with logical operator “or” | 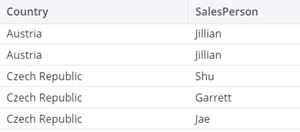 |
|


What's in this article:
Updated April 29, 2026